Spark MLlib, güçlü ve ölçeklenebilir bir platform sağlayan açık kaynaklı bir makine öğrenme kütüphanesidir. Apache Spark ekosisteminin bir bileşeni olan MLlib, makine öğrenme algoritmaları gerektiren büyük veri uygulamalarının geliştirilmesini kolaylaştırmak için tasarlanmıştır. Spark MLlib ile geliştiriciler, kolaylıkla tahmin modelleri, kümeleme algoritmaları ve öneri motorları oluşturabilirler. Kütüphane, veri ön işleme, özellik çıkarımı, model eğitimi ve değerlendirme için geniş bir araç ve algoritma yelpazesi sunarak, hızlı ve verimli bir şekilde akıllı uygulamalar geliştirmek isteyen geliştiriciler için ideal bir seçenektir. Ayrıca, Spark MLlib ölçeklenebilir bir şekilde tasarlanmış olup büyük veri kümeleriyle kolaylıkla başa çıkabilir, bu da büyük veri projeleri için ideal bir seçenek yapar. Bu makale, Spark MLlib'in genel bir bakışını ve temel özelliklerini, ayrıca akıllı uygulamalar oluşturmak için nasıl kullanılabileceğine dair bazı örneklerini sunacaktır.

Spark MLlib, Apache Spark çerçevesine dahil olan açık kaynaklı bir makine öğrenimi kütüphanesidir. Makine öğrenimi için çeşitli araçlar ve algoritmalar sağlar.
Spark MLlib, Java, Scala ve Python gibi programlama dillerini desteklemektedir.
Spark MLlib, büyük ölçekli veri kümesi işleme için ideal olan dağıtık işleme yetenekleri sunar. Ayrıca sınıflandırma, regresyon, kümeleme ve daha fazlası için geniş bir yelpazede önceden oluşturulmuş algoritmalara sahiptir.
Spark MLlib, başlayan kullanıcıların kullanması zor olabilir. Ancak, kapsamlı dokümantasyon, öğreticiler ve topluluk desteği mevcuttur ve kullanıcılara başlangıç yapmaları konusunda yardımcı olur.
Spark MLlib, derin öğrenme için sınırlı bir destek sağlar. Ancak, TensorFlow ve Keras gibi diğer derin öğrenme çerçeveleriyle sorunsuz bir şekilde entegre olur.
Spark MLlib büyük ölçekli veri kümelerini işlemek için tasarlanmıştır ve önemli hesaplama kaynakları gerektirir. Ancak, dağıtılmış işleme yetenekleri sağlar, bu da onu bir bilgisayar kümesinde çalıştırmayı mümkün kılar.
Evet, Spark MLlib gerçek zamanlı veri işleme için araçlar ve algoritmalar sağlar. Apache Kafka entegrasyonu ile akışlı veriyi işleyebilir.
Spark MLlib, çeşitli makine öğrenimi kullanım durumları için algoritmalar ve araçlar sağlar. Bununla birlikte, doğal dil işleme gibi bazı özel kullanım durumları için uygun olmayabilir.
Spark MLlib, büyük ölçekli veri kümelerini işlemek için ideal olan dağıtımlı işleme yetenekleri sunar. Ayrıca Apache Hadoop gibi diğer büyük veri araçlarıyla sorunsuz entegrasyon sağlar. Scikit-learn ve TensorFlow gibi diğer makine öğrenimi kütüphaneleri, özel kullanım durumları için daha iyi destek sağlayabilir.
Evet, Spark MLlib açık kaynak bir kütüphanedir ve ticari ve ticari olmayan amaçlarla kullanmak ücretsizdir.
| Makine Öğrenme Kütüphanesi | Geliştirici | Lisans | Yayınlanma Yılı | Dil | Ana Özellikler |
|---|---|---|---|---|---|
| TensorFlow | Apache 2.0 | 2015 | Python, C++, Java | Derin öğrenme, Sinir ağları, Takviye öğrenme | |
| Scikit-learn | Açık kaynak topluluğu | BSD | 2007 | Python | Sınıflandırma, Regresyon, Kümeleme |
| Theano | MILA | MIT | 2007 | Python | Derin öğrenme, Sembolik türetilme |
| Keras | François Chollet | MIT | 2015 | Python | Sinir ağları, Derin öğrenme |
| PyTorch | BSD | 2016 | Python | Tensor hesaplama, Derin öğrenme |


Spark MLlib, çeşitli veri analizi
problemlerini çözmek için ölçeklenebilir ve dağıtık algoritmalar sağlayan açık kaynaklı bir makine öğrenimi kütüphanesidir. Apache Spark üzerine inşa edilmiş, oldukça popüler ve yaygın olarak kullanılan
büyük veri
işleme motorudur. Spark MLlib ile sınıflandırma, regresyon, kümeleme ve işbirlikçi filtreleme gibi çeşitli makine öğrenimi görevlerini gerçekleştirebilirsiniz.
İşte Spark MLlib hakkında bilmeniz gereken bazı şeyler:
1. Ölçeklenebilirlik: Spark MLlib, Apache Spark'ın dağıtık hesaplama yeteneklerini kullanarak büyük ölçekli veri kümelerini işlemek için tasarlanmıştır. Küme üzerindeki birden çok düğümde verileri paralel olarak işleyebilir ve büyük veri hacimleriyle uğraşan kuruluşlar için ideal bir seçenek olabilir.
2. Kullanımı kolay: Spark MLlib, geliştiricilerin hızlı ve kolay bir şekilde makine öğrenimi modelleri oluşturmasına ve eğitmesine izin veren basit bir API sunar. Kütaplık aynı zamanda yaygın makine öğrenimi görevleriyle hızlı başlamayı kolaylaştıran önceden oluşturulmuş algoritmalar ve araçlar sağlar.
3. Esneklik: Spark MLlib, geniş bir veri formatı yelpazesini destekler ve yapılandırılmış ve yapılandırılmamış veriyle çalışabilir. Aynı zamanda geliştiricilere ham verilerden anlamlı özellikler çıkarmak için çeşitli özellik mühendisliği araçları sunar.
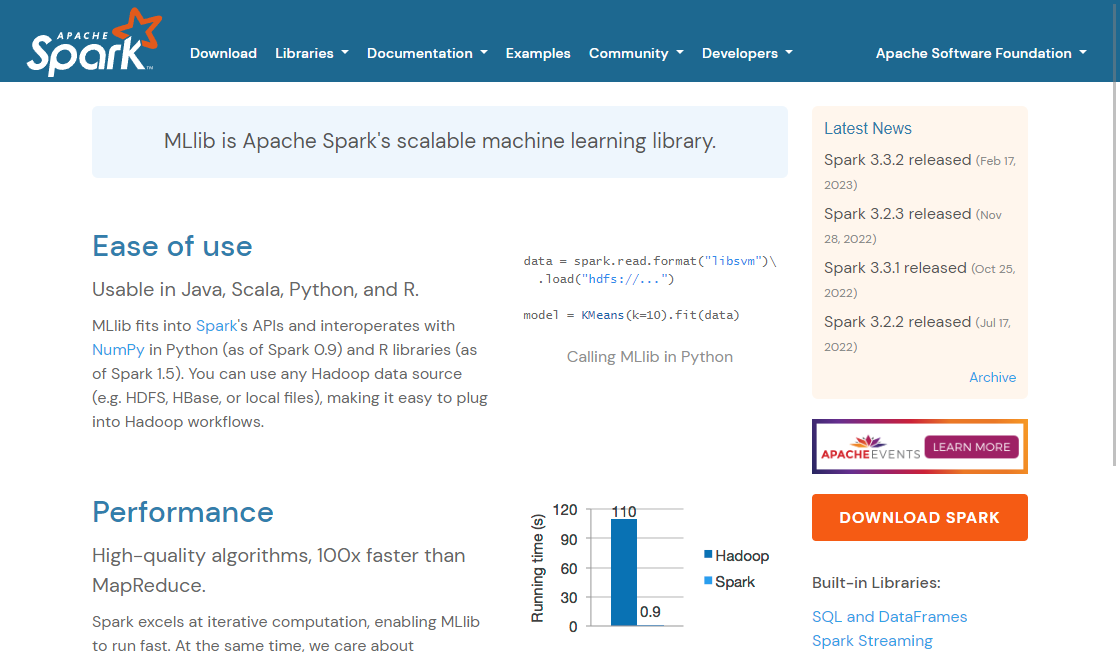
4. Performans: Spark MLlib, performans için optimize edilmiştir ve karmaşık makine öğrenimi modellerini verimli bir şekilde işleyebilir. Apache Spark'ın dağıtık hesaplama yeteneklerini kullanarak veriyi geleneksel makine öğrenimi kütüphanelerinden daha hızlı işleyebilir.
5. Entegrasyon: Spark MLlib, Spark SQL ve Spark Streaming gibi diğer Apache Spark bileşenleriyle sorunsuz bir şekilde entegre olur. Bu, makine öğrenimini daha büyük veri işleme boru hatlarına dahil etmeyi kolaylaştırır.
6. Aktif geliştirme: Spark MLlib, dünya çapında birçok katkıcının oluşturduğu geniş bir topluluk tarafından aktif olarak geliştirilen ve sürdürülen bir kütüphanedir. Kütüphaneye sürekli olarak yeni özellikler ve iyileştirmeler eklenir, böylece güncel ve güncel kalmasını sağlar.
Özetle, Spark MLlib, ölçeklenebilirlik, kullanım kolaylığı, performans, entegrasyon ve aktif geliştirme sunan güçlü ve esnek bir makine öğrenimi kütüphanesidir. Ölçekli makine öğrenimi modelleri oluşturmayı düşünüyorsanız, Spark MLlib kesinlikle değerlendirilmeye değerdir.
Topluluk için bir inceleme bırakın