Spark MLib, yapay zeka modelleri yapılandırmak ve dağıtmak için bir dizi API sunan popüler bir makine öğrenme kütüphanesidir. Apache Spark ile sorunsuz bir şekilde çalışması için tasarlanmış olan kütüphane, geliştiricilere büyük veri setleri için ölçeklenebilir ve güvenilir makine öğrenme boru hatları oluşturma imkanı sağlar. Kütüphane, sınıflandırma, regresyon, kümeleme ve öneri sistemleri gibi görevler için kullanılabilecek geniş bir algoritma ve araç yelpazesi içerir. Spark MLib, aynı zamanda daha hızlı model eğitimi ve dağıtımı için paralel hesaplama desteği sunar. Kullanıcı dostu arayüzü ve güçlü özellikleri sayesinde, Spark MLib endüstride en yaygın kullanılan makine öğrenme kütüphanelerinden biri haline gelmiştir. Bu makalede, Spark MLib'in yeteneklerini ve çeşitli uygulamalarda makine öğrenme modelleri oluşturmak ve dağıtmak için nasıl kullanılabileceğini keşfedeceğiz. Ayrıca, Spark MLib kullanmanın avantajlarını ve sınırlamalarını tartışacak ve gerçek dünya kullanım örnekleri sunacağız.

Spark MLib, makine öğrenimi modelleri oluşturmak ve dağıtmak için kullanılan bir dizi API'dir.
Spark MLib, Java, Scala ve Python gibi programlama dillerini desteklemektedir.
Evet, Spark MLib hem toplu işleme hem de gerçek zamanlı işleme için kullanılabilir.
Spark MLib, kümeleme, sınıflandırma, regresyon ve öneri gibi çeşitli makine öğrenimi algoritmalarını desteklemektedir.
Evet, Spark MLib açık kaynak bir makine öğrenimi kütüphanesidir.
Spark MLib, büyük veri kümelerinin dağıtılmış işlenmesini sağlayan Apache Spark ile çalışmak üzere tasarlanmıştır.
Evet, Spark MLib TensorFlow, Keras ve diğer birçok derin öğrenme çerçevesi için destek sağlar.
Spark MLib, dağıtık hesaplama avantajından faydalanarak yüksek performans ve ölçeklenebilirlik konusunda bilinir.
Hayır, Spark MLib, ticari donanımlarda çalışabilen bir yazılım olduğu için özel donanım veya yazılıma ihtiyaç duymaz.
Evet, Spark MLib duygusal analiz, isim varlığı tanıma ve konu modelleme gibi doğal dil işleme görevlerine destek sağlar.
| Rakip | Açıklama | Ana Özellikler |
|---|---|---|
| TensorFlow | Google Brain ekibi tarafından geliştirilen açık kaynak makine öğrenimi kütüphanesi | Derin öğrenme, sinir ağları ve takviye öğrenme desteği; yüksek ölçeklenebilirlik ve özelleştirilebilirlik; Python, C++ ve Java gibi farklı programlama dilleriyle uyumluluk |
| Scikit-Learn | NumPy ve SciPy üzerine inşa edilmiş açık kaynak makine öğrenimi kütüphanesi | Veri madenciliği ve veri analizi için kolay kullanımlı ve verimli araçlar; çeşitli denetimli ve denetimsiz öğrenme algoritmalarını destekler; Python ile uyumluluk |
| Keras | Python ile yazılmış açık kaynak derin öğrenme kütüphanesi | Sinir ağları inşa etmek ve eğitmek için kullanıcı dostu bir API; evrişimli ve tekrarlayan sinir ağları desteği; TensorFlow ve Theano ile uyumluluk |
| PyTorch | Facebook AI Research tarafından geliştirilen açık kaynak makine öğrenimi kütüphanesi | Dinamik hesaplama grafiği hata ayıklamayı ve daha hızlı geliştirmeyi kolaylaştırır; hem CPU hem de GPU hesaplamalarını destekler; Python ile uyumluluk |
| Microsoft Azure Machine Learning | Microsoft tarafından sağlanan bulut tabanlı makine öğrenimi hizmeti | Makine öğrenimi modelleri oluşturma ve dağıtma için kullanıcı dostu bir arayüz; Python ve R dilleri de dahil olmak üzere çeşitli programlama dillerini destekler; Power BI ve Excel gibi diğer Microsoft hizmetleriyle entegrasyon |


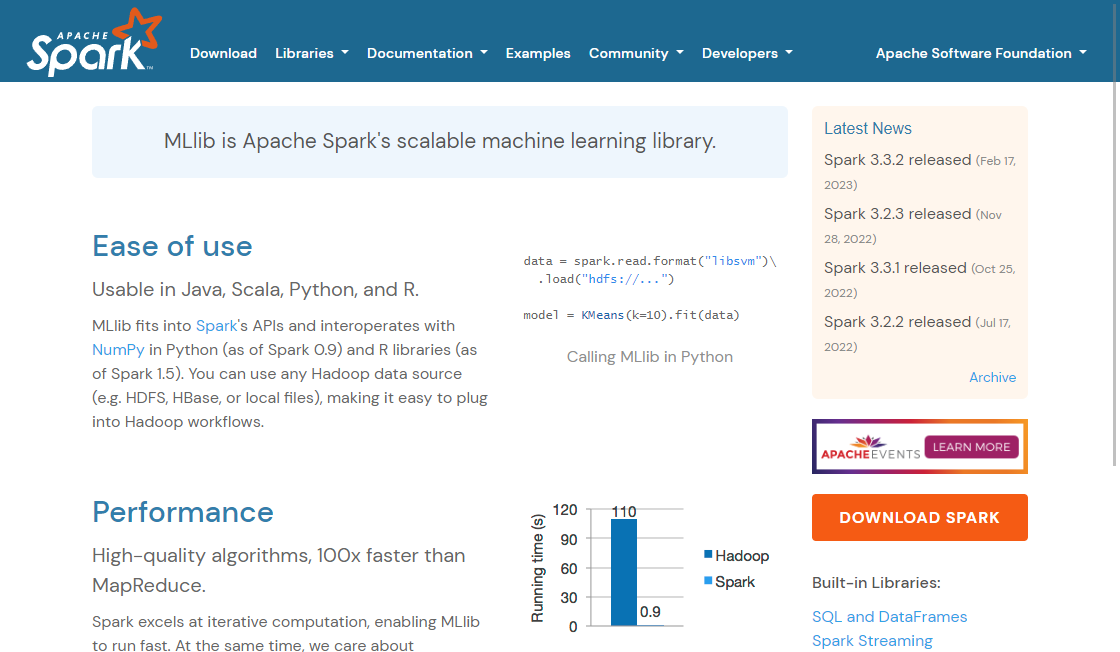
Spark MLib, geliştiricilerin kolayca makine öğrenme modelleri oluşturup dağıtabilmelerini sağlayan API'lerden oluşan bir kümedir. Apache Spark ile çalışmak üzere tasarlanmış bir makine öğrenme kütüphanesidir, hızlı ve genel amaçlı bir kümeleme hesaplama sistemi.
İşte Spark MLib hakkında bilmeniz gereken bazı önemli şeyler:
1. Spark MLib, bir dizi makine öğrenme algoritması sağlar.
Spark MLib, sınıflandırma, regresyon, kümeleme, işbirlikçi filtreleme ve boyut azaltma gibi çeşitli makine öğrenme algoritmaları sunar. Ayrıca, özellik çıkarımı, dönüştürme ve seçimi için araçlar da içerir.
2. Ölçeklenebilirdir
Spark MLib'in en büyük avantajlarından biri ölçeklenebilirliğidir. Büyük veri kümeleri ile başa çıkabilir ve hesaplamaları birden fazla makine üzerinde paralelleştirir. Bu, geleneksel makine öğrenme araçlarının zorlandığı büyük veri uygulamaları için uygundur.
3. Kullanımı kolaydır
Spark MLib, geliştiricilerin makine öğrenme modelleri oluşturup dağıtmalarını kolaylaştıran kullanıcı dostu bir API sağlar. API, sezgisel ve basit olacak şekilde tasarlanmıştır, bu da hem başlangıç düzeyindeki hem de deneyimli geliştiriciler için erişilebilir kılar.
4. Diğer Spark bileşenleriyle iyi entegre olur
Spark MLib, Spark SQL, Spark Streaming ve GraphX gibi diğer Spark bileşenleriyle sorunsuz bir şekilde entegre olur. Bu, veri temizleme, işleme ve makine öğrenme gibi end-to-end veri akışları oluşturmayı mümkün kılar.
5. Birden fazla programlama dilini destekler
Spark MLib, Java, Scala, Python ve R gibi birden fazla programlama dilini destekler. Bu, geliştiricilerin tercih ettikleri dili Spark MLib ile çalışmak için kullanabilmeleri anlamına gelir.
Sonuç olarak, makine öğrenme modelleri oluşturup dağıtmak isteyen geliştiriciler için Spark MLib harika bir seçenektir. Ölçeklenebilirliği, kullanım kolaylığı ve diğer Spark bileşenleriyle entegrasyonu, geniş bir veri bilimi görevlerini ele alabilecek güçlü bir araç haline getirir.
Topluluk için bir inceleme bırakın