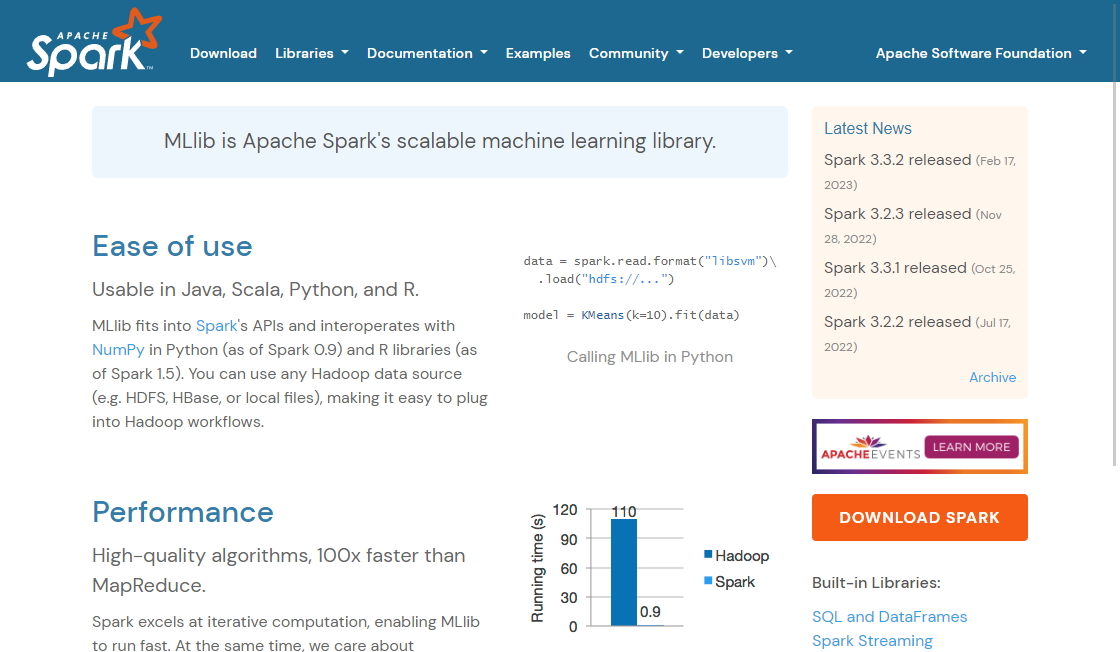
Apache Spark MLLib, güçlü ve ölçeklenebilir bir makine öğrenimi kitaplığıdır. Sınıflandırma, regresyon, kümeleme ve dahası gibi yaygın öğrenme algoritmaları sunar. Bu açık kaynaklı kitaplık, büyük ölçekli veri işleme ve analiz görevlerini ele almak üzere tasarlanmıştır, bu da büyük veri uygulamaları için ideal bir araç yapar. Gelişmiş özellikleri ve sezgisel arayüzü ile Apache Spark MLLib, işletmelere ve kuruluşlara kısa sürede ve verimli bir şekilde büyük veri miktarlarından değerli bilgiler çıkarmalarını sağlar. Tahmin modelleri oluşturmaya, müşteri davranışlarını analiz etmeye veya iş süreçlerini optimize etmeye çalışıyor olun, bu kütüphane hedeflerinize ulaşmanız için ihtiyacınız olan araçları sağlar. Apache Spark MLLib ile, makine öğrenimi teknolojisindeki en son yenilikleri kullanarak endüstrinizde rekabet avantajı elde edebilir ve özgüvenle veri tabanlı kararlar alabilirsiniz.

Apache Spark MLLib, sınıflandırma, regresyon ve kümeleme dahil olmak üzere bir dizi yaygın makine öğrenimi algoritması sunan ölçeklenebilir bir makine öğrenimi kütüphanesidir.
Apache Spark MLLib, ölçeklenebilirlik, hız ve kullanım kolaylığı gibi birçok avantaj sunar. Büyük veri uygulamaları için ideal bir seçim olan Spark MLLib, büyük veri kümelerini işleyebilir ve hesaplamaları hızlı bir şekilde gerçekleştirebilir.
Apache Spark MLLib, karar ağaçları, rastgele ormanlar, doğrusal regresyon, lojistik regresyon, k-means kümeleme ve daha pek çok yaygın makine öğrenme algoritması içermektedir.
Apache Spark MLLib, verileri bir küme içindeki birden fazla düğüme dağıtarak büyük veri setleriyle başa çıkmak için tasarlanmıştır. Bu, paralel işleme ve daha hızlı hesaplama süreleri sağlar.
Evet, Apache Spark MLLib Spark SQL ve Spark Streaming gibi diğer Apache Spark bileşenleriyle sorunsuz bir şekilde çalışması için tasarlanmıştır.
Apache Spark MLLib bazı derin öğrenme yetenekleri sunsa da, temel olarak geleneksel makine öğrenme görevleri için tasarlanmıştır. Daha gelişmiş derin öğrenme uygulamaları için, diğer kütüphaneler daha uygun olabilir.
Apache Spark MLLib, basit bir API ve net dokümantasyonu ile kullanıcı dostudur. Sınırlı makine öğrenme deneyimi olan kullanıcılar bile hızla başlayabilirler.
Evet, Apache Spark MLLib Java, Python ve R gibi birçok programlama dilini desteklemektedir.
Evet, Apache Spark MLLib açık kaynak bir projedir ve Apache 2.0 lisansı altında lisanslanmıştır.
Apache Spark MLLib öncelikle toplu işleme için tasarlanmıştır, bu nedenle gerçek zamanlı uygulamalar için en iyi seçenek olmayabilir. Ayrıca, makine öğrenmeye yeni başlayan kullanıcılar için öğrenme eğrisi dik olabilir.
| Rakip | Açıklama | Ana Özellikler | Avantajlar | Dezavantajlar |
|---|---|---|---|---|
| TensorFlow | Veri akışı ve farklılaşabilir programlama için açık kaynaklı yazılım kütüphanesi. | Sinir ağları, derin öğrenme, takviyeli öğrenme, vb. | Yüksek ölçeklenebilirlik, dağıtılmış hesaplama desteği, büyük bir topluluk. | Yüksek öğrenme eğrisi, Python konusunda uzmanlık gerektirir. |
| Scikit-learn | Python için açık kaynaklı makine öğrenimi kütüphanesi. | Sınıflandırma, regresyon, kümeleme, boyut indirgeme, model seçimi, ön işleme. | Kullanımı kolay, başlangıç seviyesine uygun, küçük ve orta ölçekli veri kümelerinde iyi performans gösterir. | Sınırlı ölçeklenebilirlik, büyük verileri işlemek için uygun değildir. |
| H2O.ai | Makine öğrenimi iş akışlarını otomatikleştiren açık kaynaklı bir makine öğrenimi platformu. | AutoML, derin öğrenme, doğal dil işleme, zaman serisi tahmini. | Kullanımı kolay, dağıtılmış hesaplama desteği, otomatik özellik mühendisliği sunar. | Sınırlı esneklik, karmaşık modelleme görevleri için uygun olmayabilir. |
| IBM Watson Studio | Veri bilimi ve makine öğrenimi için bulut tabanlı bir platform. | AutoAI, model oluşturma, dağıtım, iş birliği. | Kullanıcı dostu arayüz, çeşitli programlama dillerini destekler, önceden oluşturulmuş modeller sunar. | Sınırlı ölçeklenebilirlik, diğer seçeneklere göre daha pahalı olabilir. |
| Microsoft Azure Machine Learning | Makine öğrenimi modelleri oluşturma, eğitme ve dağıtma için bulut tabanlı bir platform. | AutoML, derin öğrenme, bilişsel hizmetler, vb. | Diğer Microsoft ürünleriyle kolay entegrasyon, çeşitli programlama dillerini destekler, önceden oluşturulmuş modeller sağlar. | Sınırlı esneklik, başlayanlar için biraz öğrenme eğrisi gerektirebilir. |


Apache Spark MLLib, sınıflandırma, regresyon, kümeleme ve daha fazlası için geniş bir kullanılan algoritma yelpazesi sunan güçlü ve ölçeklenebilir bir makine öğrenme kütüphanesidir. Bu kütüphane, büyük ölçekli veri kümelerinin hızlı ve verimli işlenmesini sağlayan Apache Spark platformu üzerine inşa edilmiştir.
Apache Spark MLLib'in en önemli avantajlarından biri, büyük verileri verimli bir şekilde işleyebilme yeteneğidir. Belleğe sığmayacak kadar büyük veri kümeleriyle çalışabilir ve dağıtılmış işleme yetenekleri, birden çok makineye yayılmış veri kümelerini işleyebilmesini sağlar.
Kütüphane, lojistik regresyon, karar ağaçları, destek vektör makineleri ve k-ortalama kümeleme de dahil olmak üzere performans için optimize edilmiş bir dizi algoritma sunar. Bu algoritmalar, büyük veri kümeleriyle çalışmak için tasarlanmıştır ve gürültülü veya eksik verilerle bile doğru sonuçlar üretebilir.
Apache Spark MLLib'in diğer bir önemli özelliği ise kullanım kolaylığıdır. Kütüphane, geliştiricilerin hızlı bir şekilde makine öğrenme modelleri oluşturmasını ve dağıtmasını kolaylaştıran basit bir API sağlar. Ayrıca, veri ön işleme, model seçimi ve değerlendirme için bir dizi araç içerir, bu da makine öğrenme iş akışını optimize etmeye yardımcı olabilir.
Genel olarak, Apache Spark MLLib, geliştiriciler ve veri bilimciler için bir dizi avantaj sunan güçlü ve esnek bir makine öğrenme kütüphanesidir. Büyük verilerle mi yoksa küçük verilerle mi çalıştığınız fark etmeksizin, bu kütüphane size doğru ve ölçeklenebilir makine öğrenme modelleri oluşturma konusunda yardımcı olabilir.
Topluluk için bir inceleme bırakın